Redis Unveiled: Decoding the Secrets Behind Its Blazing Speed
Memory Implementation
Redis stores data in memory, bypassing the speed limitations of disk I/O for read and write operations
Efficient data structures
The relationship between Redis data structures and their underlying data structures is depicted in the following diagram. 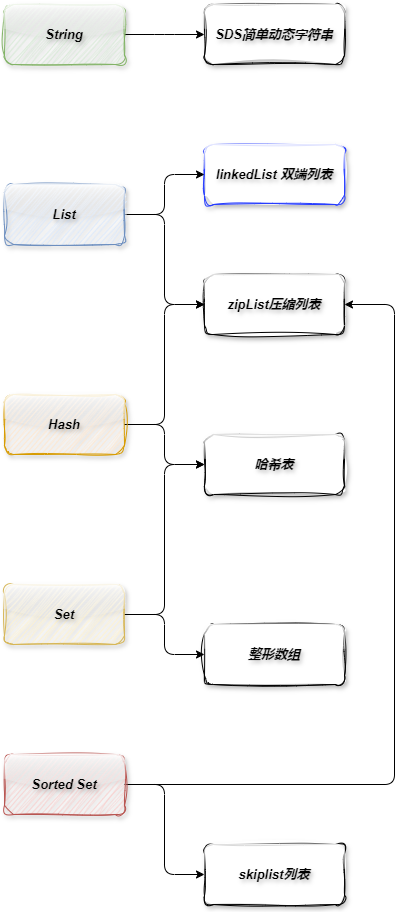
Redis Hash Dict
Redis essentially functions as a hash table to store all key-value pairs, regardless of the data type, which can be any one of the five types available. The hash table is fundamentally an array where each element is a hash bucket. Regardless of the data type, each bucket contains an entry that stores a pointer to the actual value. 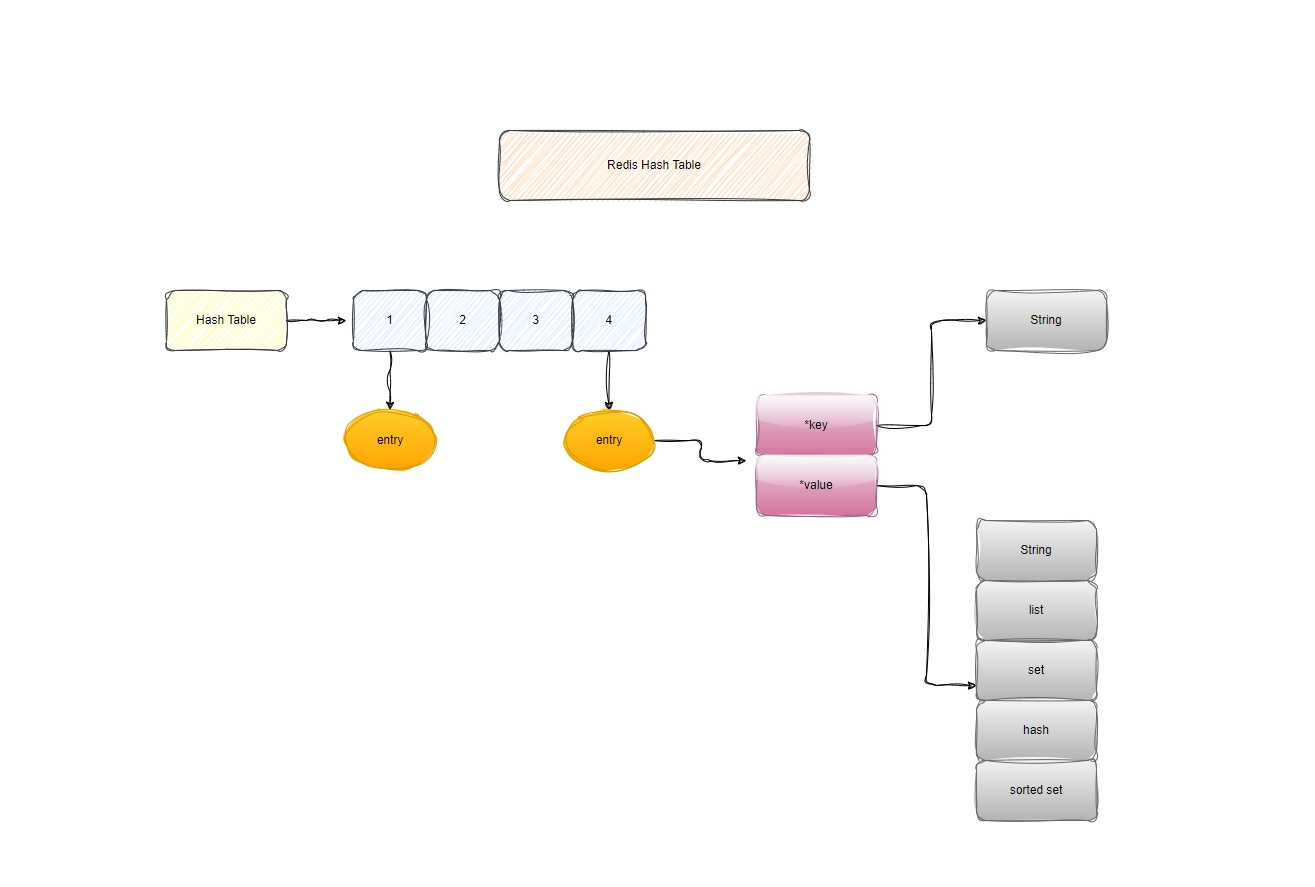
A database can be conceptualized as a hash table, where the time complexity of a hash table is O(1). This is because calculating the hash value for each key directly provides the corresponding hash bucket location. By locating the entry within the bucket, the corresponding data can be quickly found. This is one of the reasons why Redis is so fast.
Hash 冲突的解决方案:
Redis 通过链式哈希解决冲突:也就是同⼀个 桶⾥⾯的元素使⽤链表保存。但是当链表过⻓就会导致查找性能变差可能,所以 Redis 为了追求快,使⽤了两个全局哈希表。⽤于 rehash 操作,增加现有的哈希桶数量,减少哈希冲突。
开始默认使⽤ hash 表 1 保存键值对数据,哈希表 2 此刻没有分配空间。当数据越来多触发 rehash 操作,则执⾏以下操作: a. 给 hash 表 2 分配更⼤的空间; b. 将 hash 表 1 的数据重新映射拷⻉到 hash 表 2 中; c. 释放 hash 表 1 的空间。
将 hash 表 1 的数据重新映射到 hash 表 2 的过程中并不是⼀次性的,这样会造成 Redis 阻塞,⽆法提供服务。⽽是采⽤了渐进式 rehash,每次处理客户端请求的时候,先从 hash 表 1 中第⼀个索引开始,将这个位置的 所有数据拷⻉到 hash 表 2 中,就这样将 rehash 分散到多次请求过程中,避免耗时阻塞。
SDS 简单动态字符
redis 针对 c 语言的字符串上重新设计,增加了一些功能,SDS 动态字符串结构如下: 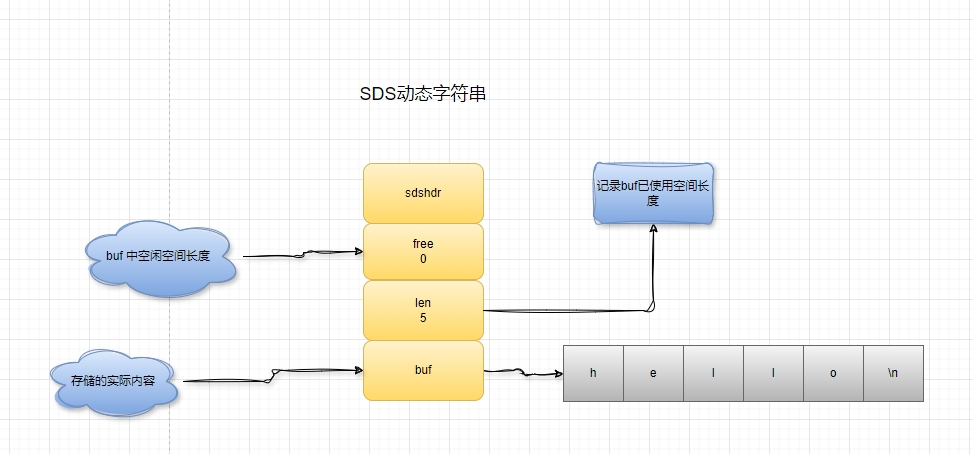
- O(1)时间复杂度获取字符串长度
SDS 中用 len 记录了字符串的长度,只需要 O(1)时间复杂度,而 C 语言中要获取字符串长度,需要循环整个字符串,时间复杂度为 O(N)
- 空间预分配
SDS 修改之后程序不仅会为 SDS 分配所需要的必须空间,还会分配额外的未使⽤空间。 分配规则如下:对 SDS 修改,len 的长度小于 1M,那么同时会分配相同长度未使用空间,例如:如果字符串长度为 10,重新分配之后,buf 长度会变成 10(已使用空间) + 10(额外空间) + 1(空字符串) = 21.如果对 SDS 修改长度大于 1M,那么就分配 1M 未使用空间
- 惰性空间释放
对 SDS 进行缩短操作时,程序不会回收多余的内存空间,而是使用 free 字段将这些字节数量记录下来不释放,后面需要 append 操作,直接使用 free 未使用的空间,减少内存的分配
zipList 压缩列表
压缩列表是 List 、hash、 sorted Set 三种数据类型底层实现之⼀。
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后⼀个元素距离压缩列表起始位置的偏移量,⽤于快速定位到最后⼀个节点
int16 zllength; // 元素个数
T[] entries; // 元素内容列表
int8 zlend; // 标志压缩列表的结束,值为0XFF
}ziplist 有一序列特殊编码的连续内存块组成的顺序型数据结构,ziplist 中可以包含多个 entry 节点,每个节点可以存放整数或者字符串 ziplist 在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表占⽤字节数、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有⼀个 zlend,表示列表结束。 需要定义第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度为 O(1),查询其他元素,就只能逐个查找,复杂度为 O(N)
双端列表
Redis List 数据类型通常被⽤于队列、微博关注⼈时间轴列表等场景。不管是先进先出的队列,还是先进后出的栈,双端列表都很好的⽀持这些特性
typedef struct list {
listNode *head; //表头节点
listNode *tail; // 表尾节点
unsigned long len; // 链表包含的节点数量
void (*dup)(void *ptr); // 节点值复制函数
void (*free)(void *ptr);// 节点值释放函数
int (*match)(void *ptr,void *key);// 节点值对比函数
}特性:
- 双端:链表节点带 prev 和 next 指针,获取某个节点的前置节点和后置节点复杂度是 O(1)
- 无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问以 NULL 为终点
- 带表头指针和表尾指针通过 list 结构的 head 指针和 tail 指针,程序获取链表的表头节点和表尾节点的复杂度 O(1)
- 带链表⻓度计数器:程序使⽤ list 结构的 len 属性来对 list 持有的链表节点进⾏计数,程序获取链表中节点数量的复杂度为 O(1)
- 多态::链表节点使⽤ void* 指针来保存节点值,并且可以通过 list 结构的 dup、free、match 三个属性为节点值设置类型特定函数,所以链表可以⽤于保存各种不同类型的值
后续版本对列表数据结构进⾏了改造,使⽤ quicklist 代替了 ziplist 和 linkedlist。 quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每⼀段使⽤ ziplist 来紧凑存储,多个 ziplist 之间使⽤双向指针串接起来。 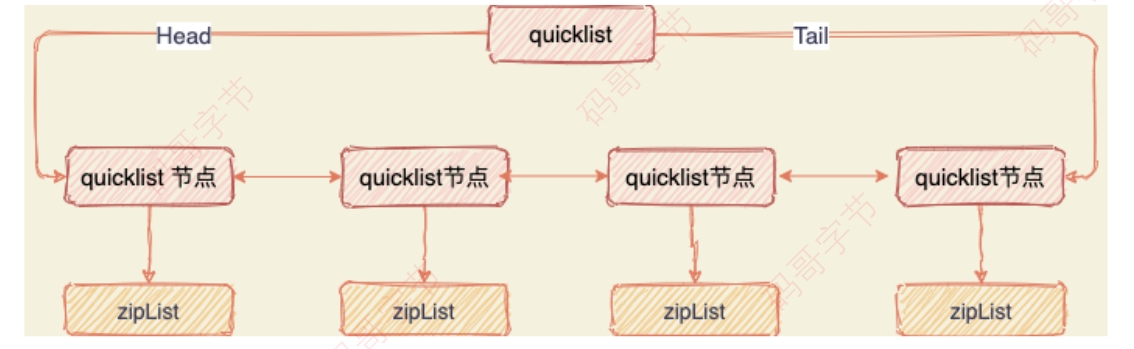
skipList 跳表
sorted set 类型的排序功能便是通过「跳跃列表」数据结构来实现 跳跃表(skiplist)是⼀种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从⽽达到快速访问节点的目的 跳跃表⽀持平均 O(logN)、最坏 O(N)复杂度的节点查找,还可以通过顺序性操作来批量处理节点 跳表在链表的基础上,增加了多层级索引,通过索引位置的⼏个跳转,实现数据的快速定位,如下图所示: 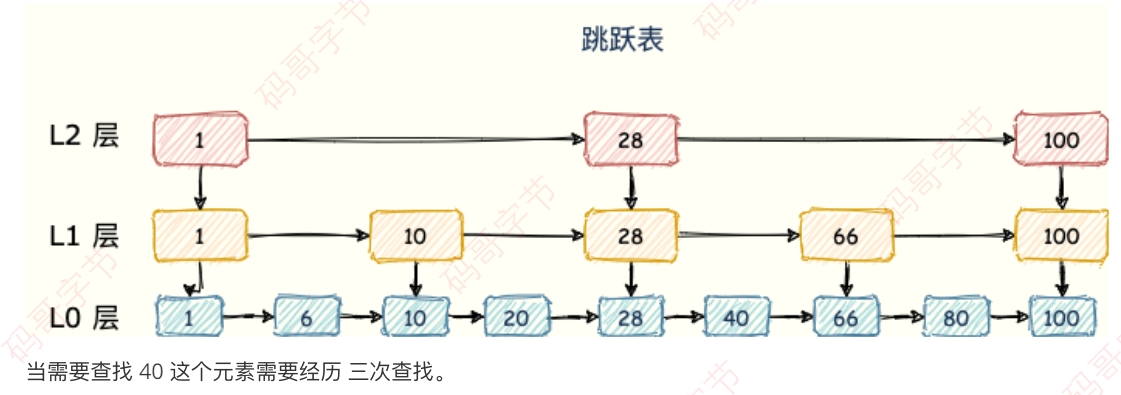
整数数组(intset)
当一个集合只包含整数型元素,元素不多时, redis 就会使用整数集合为集合键的底层实现
typedef struct intset {
uint32_t encoding; //编码方式
uint32_t length; // 集合包含的元素数量
int8_t contents[]; // 保存元素的数组
}contents 数组是整数集合的底层实现:整数集合的每个元素都是 contents 数组的⼀个数组项(item),各个项在数组中按值的⼤⼩从⼩到⼤有序地排列,并且数组中不包含任何重复项。length 属性记录了整数集合包含的元素数量,也即是 contents 数组的⻓度。
单线程模型
Redis 单线程指的是 Redis 的网络 IO 以及键值对指令读写是由一个线程来执行。但是 Redis 持久化,集群数据同步,异步删除都是其他线程执行 单线程模型的好处:
- 不会因为线程创建导致性能消耗
- 避免上下文切换引起的 CPU 消耗,没有多线程切换的开销
- 避免了线程之间的竞争问题
单线程是基于内存财政,CPU 不是 Redis 的瓶颈,Redis 瓶颈最有可能是机器内存的大小或者网络带宽。参考https://redis.io/docs/latest/develop/get-started/faq/
I/O 多路复用模型
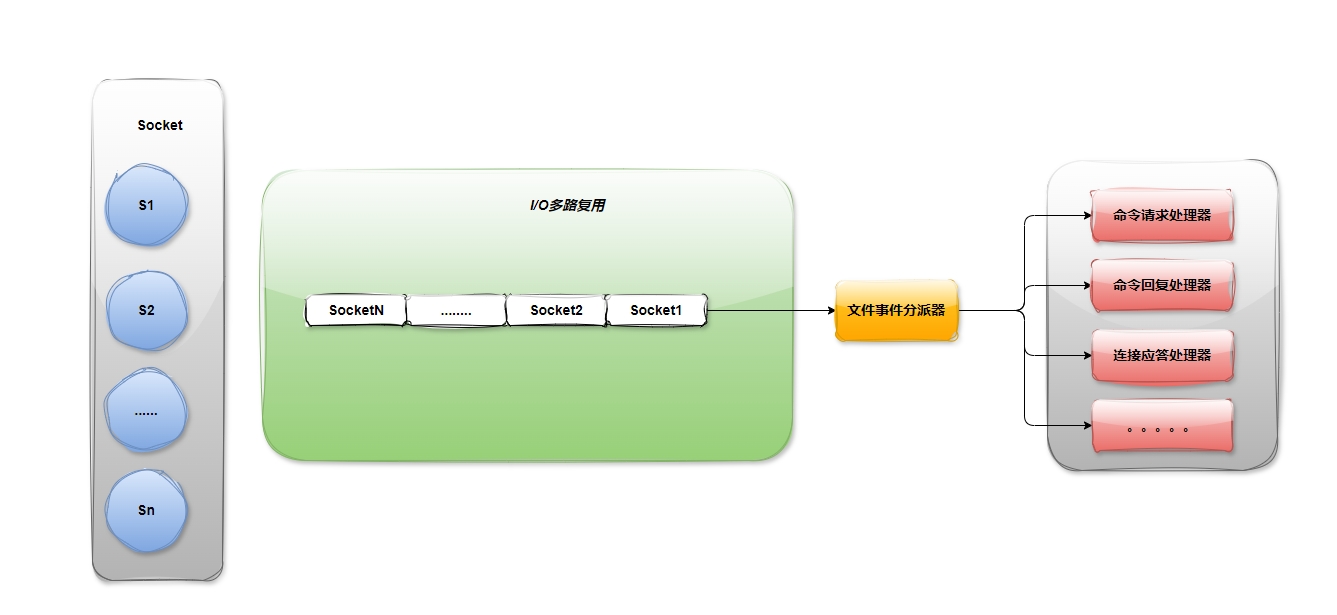 Redis 线程不会阻塞在某⼀个特定的监听或已连接套接字上,也就是说,不会阻塞在某⼀个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从⽽提升并发性
Redis 线程不会阻塞在某⼀个特定的监听或已连接套接字上,也就是说,不会阻塞在某⼀个特定的客户端请求处理上。正因为此,Redis 可以同时和多个客户端连接并处理请求,从⽽提升并发性